‘The entire protein universe’: AI predicts shape of nearly every known protein
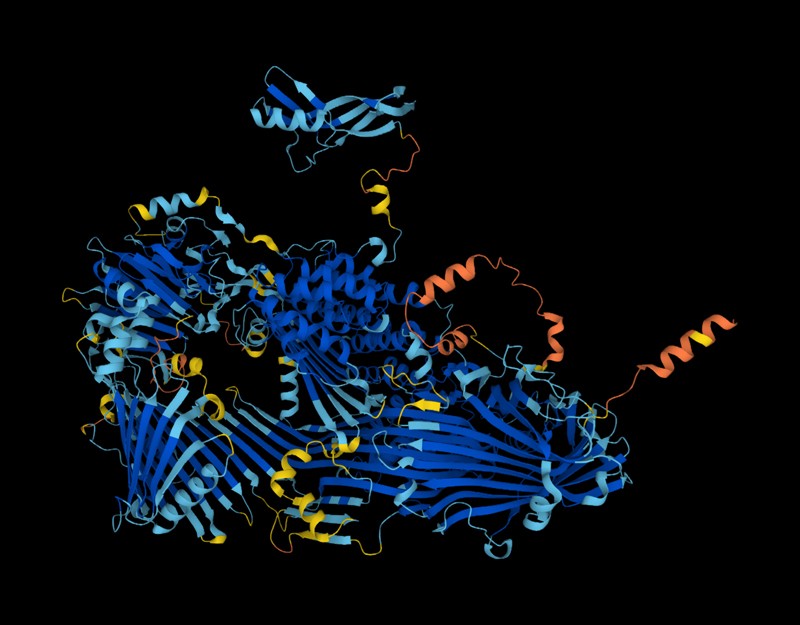
The structure of the vitellogenin protein — a precursor of egg yolk — as predicted by the AlphaFold tool.Credit: DeepMind
From today, determining the 3D shape of almost any protein known to science will be as simple as typing in a Google search.
Researchers have used AlphaFold — the revolutionary artificial-intelligence (AI) network — to predict the structures of more than 200 million proteins from some 1 million species, covering almost every known protein on the planet.
The data dump is freely available on a database set up by DeepMind, the London-based AI company, owned by Google, that developed AlphaFold, and the European Molecular Biology Laboratory’s European Bioinformatics Institute (EMBL–EBI), an intergovernmental organization near Cambridge, UK.

What’s next for AlphaFold and the AI protein-folding revolution
“Essentially you can think of it covering the entire protein universe,” DeepMind chief executive Demis Hassabis said at a press briefing. “We’re at the beginning of a new era of digital biology.”
The 3D shape, or structure, of a protein is what determines its function in cells. Most drugs are designed using structural information, and the creation of accurate maps of proteins’ amino-acid arrangement is often the first step to making discoveries about how proteins work.
DeepMind developed the AlphaFold network using an AI technique called deep learning, and the AlphaFold database was launched a year ago with more than 350,000 structure predictions covering nearly every protein made by humans, mice and 19 other widely studied organisms. The catalogue has since swelled to around 1 million entries.
“We’re bracing ourselves for the release of this huge trove,” says Christine Orengo, a computational biologist at University College London, who has used the AlphaFold database to identify new families of proteins. “Having all the data predicted for us is just fantastic.”
High-quality structures
The release of AlphaFold last year made a splash in the life-sciences community, whose members have since been scrambling to take advantage of the tool. The network produces highly accurate predictions of many proteins’ structures. It also provides information about the accuracy of its predictions, so researchers know whether they can be relied on. Conventionally, scientists have needed to use time-consuming and costly experimental methods such as X-ray crystallography and cryo-electron microscopy to solve protein structures.
According to EMBL–EBI, around 35% of the more than 214 million predictions are deemed to be highly accurate, which means they are as good as experimentally determined structures. Another 45% are considered to be accurate enough for many applications.
‘It will change everything’: DeepMind’s AI makes gigantic leap in solving protein structures
Many AlphaFold structures are good enough to replace experimental structures for some applications. In other cases, researchers use AlphaFold predictions to validate and make sense of experimental data. Poor predictions are often obvious, and some of them are caused by intrinsic disorder in the protein itself that means it has no defined shape — at least, not without other molecules present.
The 200 million predictions released today are based on the sequences in another database, called UniProt. It’s likely that scientists will have already had an idea about the shapes of some of these proteins, because they are included in databases of experimental structures or resemble other proteins in such repositories, says Eduard Porta Pardo, a computational biologist at Josep Carreras Leukaemia Research Institute (IJC) in Barcelona, Spain.

DeepMind chief executive Demis Hassabis says AlphaFold’s new database covers “the entire protein universe”.Credit: Jung Yeon-Je/AFP/Getty
But such entries tend to be skewed toward human, mouse and other mammalian proteins, Porta says. It’s likely that the AlphaFold dump will add significant knowledge, because it includes such a diverse range of organisms. “It’s going to be an awesome resource. And I’m probably going to download it as soon as it comes out,” says Porta.
Because AlphaFold’s software has been available for a year, researchers have already had the capacity to predict the structure of any protein they wish. But many say that the availability of predictions in a single database will save researchers time, money — and faff. “It’s another barrier of entry that you remove,” says Porta. “I’ve used a lot of AlphaFold models. I have not ever run AlphaFold myself.”
Jan Kosinski, a structural modeller at EMBL Hamburg in Germany who has been running the AlphaFold network over the past year, can’t wait for the database expansion. His team once spent three weeks predicting the proteome — the set of all of an organism’s proteins — of a pathogen. “Now we can just download all the models,” he said at the briefing.
Twenty-three terabytes
Having almost every known protein in the database will also make new types of study possible. Orengo and her team have used the AlphaFold database to identify new kinds of protein families, and they will now do this on a much larger scale. She and her colleagues will also use the expanded database to help them understand the evolution of proteins with helpful properties — such as the ability to consume plastic — or worrying ones, like those that can drive cancer. The identification of distant relatives of these proteins in the database can pinpoint the basis for their properties.
Martin Steinegger, a computational biologist at Seoul National University who helped to develop a cloud-based version of AlphaFold, is excited about seeing the database expand. But he says that researchers are still likely to need to run the network themselves. Increasingly, people are using AlphaFold to determine how proteins interact, and such predictions are not in the database. Other predictions that are not currently there include microbial proteins identified by sequencing genetic material from soil, ocean water and other ‘metagenomic’ sources.
Some sophisticated applications of the expanded AlphaFold database might also depend on downloading its entire 23-terabyte contents, which won’t be feasible for many teams, Steinegger says. Cloud-based storage could also prove costly. Steinegger has co-developed a software tool called FoldSeek that can quickly find structurally similar proteins and which should also be able to squash the AlphaFold data down considerably.
Even with almost every known protein included, the AlphaFold database will need updating as new organisms are discovered. AlphaFold’s predictions can also be improved as new structural information becomes available. Hassabis says DeepMind has committed to supporting the database for the long haul, and that he can see updates occurring annually.
His hope is that the availability of the AlphaFold database will have a lasting impact on the life sciences. “It’s going to require quite a big change in thinking.”
Nature 608, 15-16 (2022)
doi: https://doi.org/10.1038/d41586-022-02083-2
UPDATES & CORRECTIONS
-
Correction 29 July 2022: An earlier version of the standfirst wrongly stated that AlphaFold had determined protein structures from nearly every known species. In fact, it has determined protein structures from nearly every organism with protein sequence data.
Credit : https://www.nature.com/articles/d41586-022-02083-2